Event Sourcing in C# - Best Practices and Implementation Tips

Event sourcing is a powerful technique used in software development that has gained significant popularity over the years. It involves capturing and storing every event that occurs within an application, allowing developers to reconstruct the state of the application at any given point in time. In C#, event sourcing can be implemented using frameworks such as EventStore or NEventStore, which provide tools for capturing and storing events.
One of the key benefits of using event sourcing in C# is its ability to simplify complex business logic by breaking it down into smaller, more manageable events. This approach allows developers to focus on individual events rather than trying to understand the entire system at once. Additionally, because every event is captured and stored, it provides a complete audit trail of all changes made within the system.
However, implementing event sourcing in C# requires careful consideration of various factors such as data storage and retrieval as well as the potential impact on application performance. Developers must ensure that they have adequate resources available to handle large volumes of events while maintaining acceptable response times.
Modeling an Aggregate with Event Sourcing: The Port Model, CQRS, and Read Model
The Port Model is a powerful way to model an aggregate with event sourcing, CQRS, and read models. In this section, we'll explore the key concepts behind the Port Model and how it can be used to create more efficient and effective applications.
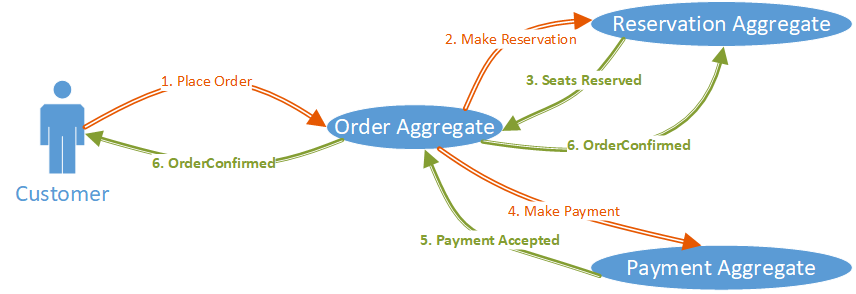
Aggregates are at the heart of event sourcing. They encapsulate the state changes of an application and emit events when they are modified. The write model of an aggregate is responsible for handling incoming commands and generating events that represent the changes made to the aggregate's state.
The read model is a separate representation of the aggregate's state that is optimized for querying and reading data. It provides a view of the current state of an aggregate in a format that is easy to work with.
In the Port Model, the read model is designed to provide a view of the aggregate's state that is specific to a particular client or port. This allows us to optimize our read models for specific use cases, which can greatly improve performance and reduce complexity.
For example, let's say we have an application that tracks shipments between ports. We might have several different clients who need access to this data - shipping companies, customs officials, freight forwarders, etc. Each client has different requirements for how they want to see this data.
With traditional read models, we would need to create a single view that satisfies all these requirements. This can be difficult because each client may have conflicting needs or require different levels of detail.
Port model
With the Port Model, we can create separate views for each client or port. For example, our shipping company might only care about shipments leaving from their own ports. So we could create a read model specifically for them that only shows shipments leaving from their ports.
This makes it much easier to manage our read models because we don't need to worry about conflicting requirements or complex queries. Instead, we can focus on creating simple views that satisfy each client's needs.
Another benefit of the Port Model is that it allows us to easily handle complex relationships between aggregates. For example, let's say we have an aggregate that represents a shipment and another aggregate that represents a container. We might need to show which containers are currently on each shipment.
With traditional read models, this can be difficult because we need to join data from multiple aggregates. This can be slow and error-prone, especially if the relationship between the aggregates is complex.
With the Port Model, we can create a separate view for each port that includes all the information needed to display shipments and containers together. This makes it much easier to manage our data and ensures that each client gets exactly what they need.
The Domain Model and Domain Event Classes
In event sourcing architecture, the domain model represents the business domain and serves as the foundation for the entire system. It is a critical component that defines how data is stored, processed, and presented to users. The domain model consists of entities, value objects, and aggregates that represent various aspects of the business domain.
Domain events are used to capture changes in the state of the domain model. They are stored in an event store and can be replayed to reconstruct past states of the system. This enables developers to track changes over time and analyze how data has evolved.
Domain event classes define the structure of events and should be designed to reflect the business domain. Each class should correspond to a specific type of event that occurs within the system. For example, if an order is placed in an e-commerce application, there might be an OrderPlacedEvent class that captures all relevant information about that event.
It's important to choose appropriate event types that accurately represent changes being made to the domain model. This helps ensure consistency across different parts of the system and makes it easier for developers to understand what's happening at any given time.
Database structure for event sourcing
The database structure for event sourcing is different from traditional databases because it focuses on storing events rather than entities. Interfaces and classes should be designed accordingly with a focus on methods for retrieving and storing events.
One approach is to use a document database such as MongoDB or RavenDB which allows for flexible schema design while still providing powerful querying capabilities. Another option is using a relational database like SQL Server or PostgreSQL but with a modified schema design optimized for storing events instead of entities.
When designing interfaces and classes for working with event stores, it's important to consider factors such as performance, scalability, maintainability, and ease of use. Developers need efficient ways to retrieve specific sets of events based on criteria such as time range or entity type.
For example, suppose we have a shopping cart class in an e-commerce application. We might define methods such as GetCartEventsByDateRange(DateTime startDate, DateTime endDate) or GetCartEventsByItemType(string itemType) to retrieve events related to specific carts or items.
Replaying Events and Building Projections with Marten
Marten is a powerful event-sourcing library for C# that allows developers to replay events and build projections easily. With Marten, developers can create materialized views that represent the current state of an example project, ensuring eventual consistency across the application.
Projections in Marten can be built using event-storming techniques, allowing developers to model their domain events and create concrete implementations that accurately reflect the actual events in the system. This approach helps ensure consistency between development and test environments, making it easier to identify and fix issues before they become major problems.
Using snapshots in Marten can help optimize projection performance by allowing developers to store only the changes between the current and previous states of a project. This reduces the need to replay all events from scratch, which can be time-consuming and resource-intensive.
The benefit of using Marten
One of the key benefits of using Marten is its ability to provide eventual consistency across an application. Eventual consistency means that updates made to one part of an application will eventually propagate throughout the entire system, ensuring that all users see consistent data regardless of where they are located or what device they are using.
To achieve eventual consistency with Marten, developers must first define their domain events using event-storming techniques. Once these events have been defined, they can be used to build projections that represent the current state of an example project.
By using snapshots in conjunction with projections, developers can optimize performance while still maintaining eventual consistency across their applications. Snapshots allow developers to store only changes between states rather than having to replay every single event from scratch each time there is a change.
Marten also provides support for creating materialized views based on projections. Materialized views are precomputed summaries of data that are stored as tables in a database. They allow for faster access times when querying large datasets by providing pre-aggregated results instead of having to compute them on-the-fly each time a query is run.
When building materialized views with Marten, developers can specify the projection they want to use as the basis for their view. This ensures that the view accurately reflects the current state of the example project and is consistent with other parts of the application.
Event sourcing in C# with Marten
One of the key benefits of using Marten is its ability to support event sourcing in c#, a technique pioneered by Martin Fowler. Event sourcing involves storing every change made to an application's state as a separate event, rather than simply storing the current state.
This approach provides several benefits, including improved audibility and traceability, easier debugging and testing, and better support for distributed systems. By using Marten for event sourcing in C#, developers can easily replay events and rebuild projections based on those events.
For example, let's say we have an e-commerce application that allows users to add items to a shopping cart. When a user adds an item to their cart, an "item added" event is generated and stored in our database. We can then use this event to build a projection that represents the current state of our shopping cart.
If we later need to update our projection (for example, if we add new fields or change how data is aggregated), we can simply replay all "item added" events from our database and rebuild our projection based on those events. This makes it easy to maintain consistency across our application even as it evolves over time.
Projecting Events to Flat, Stream, and Events Tables
In event sourcing, projecting events to flat, stream, and events tables is a crucial aspect. This process involves creating tables that store event data in a way that makes it easy to query and analyze at the database level. Let's dive into each of these types of tables and their specific use cases.
Flat Tables for Displaying Event Data
Flat tables are useful for displaying event data in a tabular format. They provide an easy-to-read view of all the events that have occurred in the system. For example, if you have an e-commerce website, you might want to display all the orders placed by customers in a table format. A flat table can be used to store this information.
The structure of a flat table is straightforward: each row represents an event, and each column represents a property or attribute of that event. For instance, if we take the example of an e-commerce website again, some columns could include order ID, customer name, product name, quantity ordered, price per unit, total cost etc.
Stream Tables for Storing Events Chronologically
Stream tables are better suited for storing events in chronological order as they maintain the sequence of events as they occur over time. In contrast with flat tables which are optimized for querying large amounts of data quickly without considering time-based constraints.
A stream table stores all events related to one entity (e.g., customer) together so that it's easier to retrieve them later on when needed. This makes it possible to easily track changes made over time since every change will be stored chronologically within its respective stream.
Events Tables Provide Comprehensive View
Events tables provide a comprehensive view of all events that have occurred in the system regardless of whether they relate to one entity or not. They're typically used when you need access to all historical data about your system's behavior or when auditing is required.
An events table stores all events in a single table, with each row representing an event. The columns in the table represent the properties or attributes of that event. This makes it easy to query and analyze all events that have occurred in the system.
Database Level
At the database level, it's important to design tables that are optimized for querying and analyzing data efficiently. This means choosing appropriate data types, indexing columns that will be frequently queried, and partitioning large tables into smaller ones where necessary.
It's also important to consider how data will be accessed when designing tables. For example, if you know that you'll frequently need to retrieve all events related to one entity (e.g., customer), then it makes sense to store those events together in a stream table rather than spreading them across multiple tables or databases.
Exploring Events and Stream Tables
Event sourcing is a technique that has been gaining popularity in recent years, as it provides a way to capture and store every change made to an application's state as a series of events in an event stream. These events are stored in an event store, which is essentially a database engine optimized for storing and querying event streams. This approach allows developers to build applications that can be easily audited, debugged, and analyzed.
When using event sourcing in C#, every time the application changes its state, it generates a new event. These events are then appended to the end of the stream of uncommitted events. The term "uncommitted" refers to the fact that these events have not yet been persisted to disk or another form of durable storage.
Persisting uncommitted events
To persist these events, they are written to a table in a SQL database engine. This table is often referred to as the "event stream table." The purpose of this table is to provide a durable storage mechanism for all of the events generated by the application.
Advantages of using an event stream table:
One advantage of using an event stream table is that it allows developers to easily query and analyze the data contained within it. For example, if you wanted to know how many times a particular user performed a certain action within your application, you could write a simple SQL query against the event stream table.
Another advantage of using an event stream table is that it provides developers with an audit trail for their applications. By storing every change made to the application's state as an event in the event stream table, developers can easily see what changes were made at what time and by whom.
In addition to providing developers with an audit trail for their application, using an event stream table also makes it easier for them to implement features such as undo/redo functionality. Because every change made to the application's state is captured in the event stream table, developers can simply replay those events in reverse order to undo any changes that were made.
When using an event stream table, it is important to ensure that the table is designed in a way that allows for efficient querying and analysis. This often involves denormalizing the data contained within the events to make it easier to query.
Steam tables
One approach to denormalizing the data contained within events is to use a technique called "stream tables." A stream table is essentially a denormalized view of the event stream table that makes it easier to query and analyze the data contained within it.
Stream tables are created by taking the events contained within the event stream table and transforming them into rows in a new table. Each row in this new table represents a single event, with columns containing data from both the event itself as well as any related entities.
By creating these stream tables, developers can easily query and analyze their application's state without having to perform complex joins or other operations against the event stream table itself. This can lead to significant performance improvements when working with large datasets.
ShipTrackingService Slice: Instance Variables, Initialization, and Ship Model
Instance Variables and Initialization
The ShipTrackingService slice is a crucial component of any shipping system, responsible for tracking the locations of ships within the system. To do this effectively, the slice has several instance variables that store the current state of the system. These variables include a list of all ships in the system, along with their current locations.
Initialization of the slice involves setting up these instance variables and loading any existing state from the event store. This ensures that when the service starts up, it has access to all relevant information about each ship in the system.
One important aspect of initialization is ensuring that each ship's unique ID is properly assigned. This allows for easy identification and tracking of individual ships as they move throughout the system. Additionally, any relevant metadata about each ship can be stored alongside its ID and location data.
Ship Model
To represent each ship in the system, a Ship model is used. This model contains all relevant information about each ship, including its unique ID, current location, and other metadata such as its cargo or destination.
By using a standardized model like this for all ships within the system, it becomes much easier to track their movements and ensure that they are properly accounted for at all times. The ShipTrackingService slice can quickly retrieve information about any given ship by simply referencing its corresponding model object.
Events and Event Sourcing
The ShipTrackingService slice uses events to update the state of the system whenever a change occurs. For example, when a ship changes location or is added/removed from the system, an event is generated to reflect this change.
By using event sourcing in this way, every action taken within the shipping system is recorded as an event. This provides a complete audit trail of all actions taken within the system over time.
This approach has several benefits over traditional database-based systems. Firstly, it allows for easy rollback or replaying of events if necessary - something that would be difficult or impossible with a traditional database. Secondly, it provides a much more complete and accurate record of all actions taken within the system.
Tracking Ship Arrival and Departure Events
Ship tracking services are becoming increasingly popular as they provide real-time data on ship locations, arrivals, and departures. These services can be used to capture incoming events such as ship arrivals and departures. By implementing a ship tracking service, we can handle tracking events and manage the payload data.
Using a timer, the ship tracking service can periodically check for new tracking events and update the system accordingly. This allows us to keep track of all incoming ships in real time. The arrival and departure events can be stored as separate event types in the event store.
The benefits of using event sourcing in C#:
One of the benefits of using event sourcing is that historical data on ship arrivals and departures can be easily accessed and analyzed. By storing all events related to ships in an event store, we have a complete history of every ship that has entered or left our port.
This information is invaluable for analyzing trends in shipping traffic, identifying potential bottlenecks or delays, and improving overall efficiency. For example, if we notice that certain ships tend to arrive at our port during peak hours, we could adjust our operations to accommodate them more efficiently.
Another benefit of using event sourcing in C# is that it allows us to easily roll back changes if necessary. If there is an error in our system or a problem with a particular shipment, we can quickly identify the source of the issue by looking at the relevant events in our event store.
In addition to providing valuable insights into shipping traffic patterns, tracking services also play an important role in ensuring safety and security at ports around the world. By monitoring all incoming ships in real time, authorities can quickly identify any suspicious activity or potential threats.
For example, if a ship arrives at our port without proper documentation or appears to be carrying dangerous cargo, authorities can take immediate action to ensure public safety. Without access to real-time tracking data, it would be much more difficult to identify these types of threats before they become serious problems.
Command Handlers with Marten and Command Query Responsibility Segregation (CQRS)
In event sourcing with Marten, command handlers are responsible for executing commands that change the state of the system. In this section, we will discuss how CQRS separates the responsibility of handling commands and queries, allowing for more efficient and scalable systems. We will also explore how developers can easily execute commands and queries through the use of command handlers.
What is CQRS?
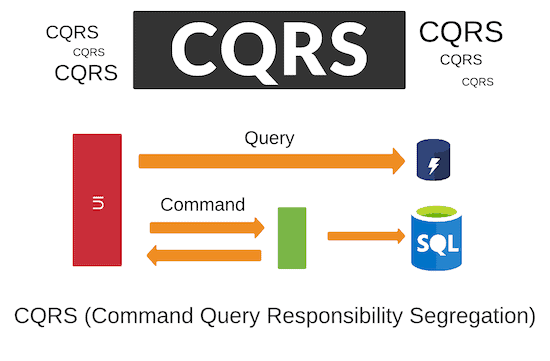
CQRS stands for Command Query Responsibility Segregation. It is a design pattern that separates the responsibility of handling commands and queries into two different parts of an application. The idea behind CQRS is to have one part of an application that handles all write operations (commands) while another part handles read operations (queries).
The benefit of using CQRS is that it allows developers to optimize each part separately. For example, since write operations tend to be more complex than read operations, developers can focus on optimizing the write side without worrying about affecting read performance.
Command Handlers in Event Sourcing with C#
In event sourcing, every change made to a system is captured as an event. These events are then stored in an event store where they can be queried or replayed at any time. When a user performs an action in a system, such as creating a new account or updating their profile information, a command is sent to the system.
A command handler takes care of processing these commands by executing business logic and generating one or more events that represent the changes made by the command. These events are then stored in the event store.
By using command handlers in conjunction with event sourcing in c#, developers can ensure that every change made to a system is captured as an event. This provides a complete audit trail of all changes made to the system over time.
Command Line Interfaces
One way to execute commands and queries in a system is through the use of command line interfaces (CLI). A CLI allows users to interact with a system by typing commands into a terminal or console.
Developers can create command handlers that are specifically designed to work with CLI tools. These command handlers can parse the input provided by the user, execute the appropriate business logic, and return the results back to the user.
Using command line interfaces in conjunction with command handlers provides developers with a powerful tool for interacting with their systems. It allows them to quickly and easily test new features, debug issues, and perform other tasks without having to use a graphical user interface (GUI).
Many companies have successfully implemented CQRS and command handlers in their systems. For example, Microsoft's Azure Cosmos DB uses CQRS to provide scalable read and write operations for their globally distributed database service.
Another example is Uber's Michelangelo platform which uses CQRS along with event sourcing to power its machine learning infrastructure. By using these patterns, they were able to build a highly scalable system that can handle millions of requests per second.
Conclusion: Key Takeaways from Event Sourcing in C#
In conclusion, event sourcing is a powerful technique for building robust and scalable applications in C#. By modeling aggregates as streams of events, we can capture the full history of changes to our domain objects and use that history to build projections for querying and reporting.
One key advantage of event sourcing is its support for optimistic concurrency. By using version numbers or timestamps to track changes to our aggregates, we can detect conflicts when multiple users try to modify the same object concurrently. This allows us to provide a smooth user experience while ensuring data consistency.
Another important concept in event sourcing in C# is command query responsibility segregation (CQRS). By separating write operations (commands) from read operations (queries), we can optimize each part of our application for its specific needs. This can lead to improved performance and scalability, especially for complex domains with many concurrent users.
To implement event sourcing in C#, we can use frameworks like Marten that provide built-in support for storing and querying event streams. We can also leverage other patterns like domain-driven design (DDD) to model our aggregates and domain events more effectively.