DDD Aggregates - Best Practices and Implementation Strategies

Introduction
Domain-Driven Design (DDD) offers a powerful approach to building software systems that align closely with real-world domains. At the heart of DDD lies the concept of aggregates, which play a crucial role in modeling complex domains effectively. In this section, we will explore the significance of best practices and implementation strategies when working with DDD aggregates.
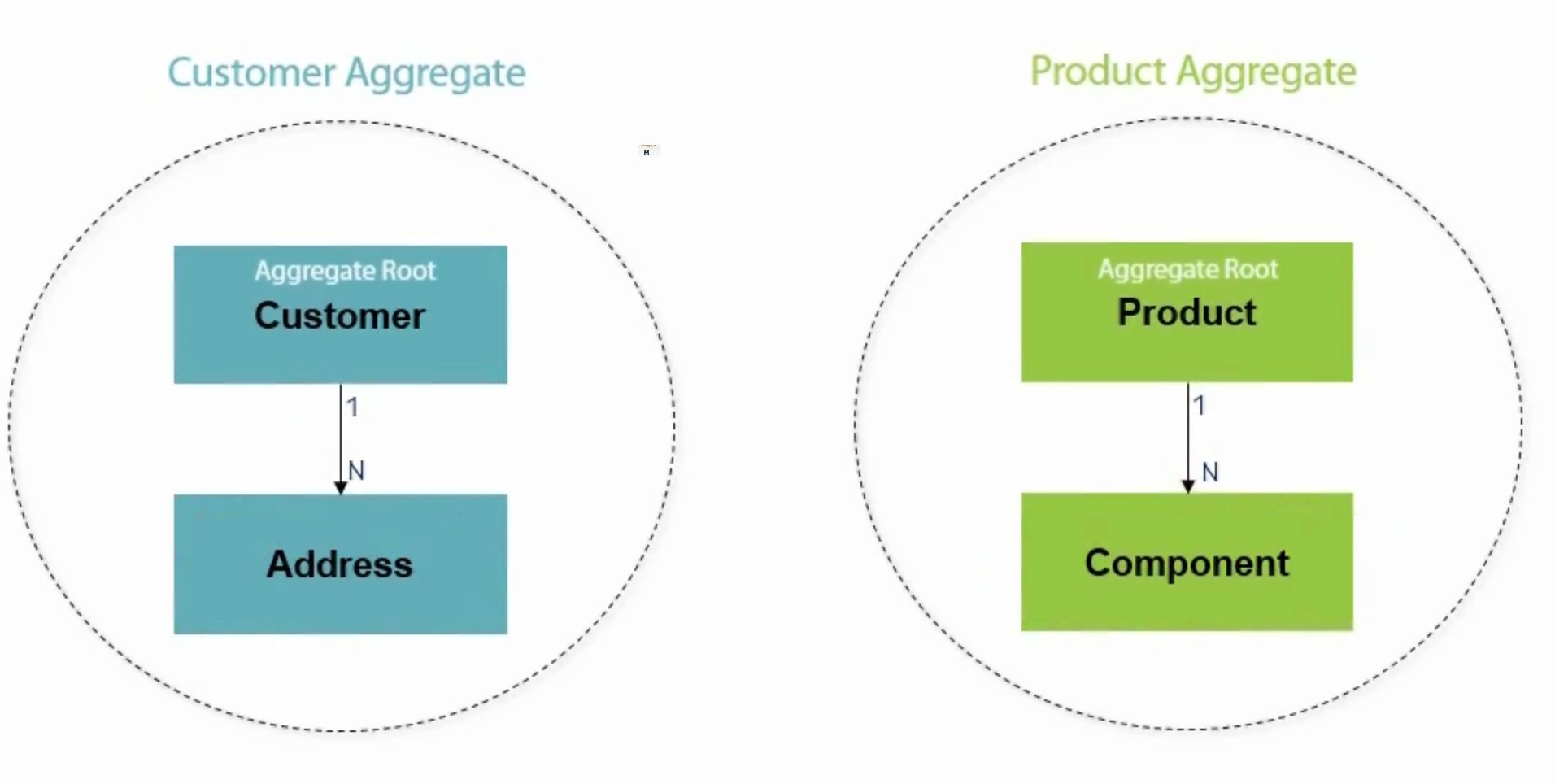
In DDD, an aggregate is a cluster of related domain entities and value objects treated as a single unit. It acts as a consistency boundary, encapsulating business rules and ensuring the integrity of the domain model. Aggregates simplify complex domains by providing clear boundaries and defining relationships between objects within the model.
While understanding the basic concepts of aggregates is essential, it is equally important to adopt best practices and implement effective strategies when working with DDD aggregates. Best practices guide developers in making informed design decisions and help ensure the creation of maintainable, scalable, and extensible domain models.While understanding the basic concepts of aggregates is essential, it is equally important to adopt best practices and implement effective strategies when working with DDD aggregates. Best practices guide developers in making informed design decisions and help ensure the creation of maintainable, scalable, and extensible domain models.
Implementation strategies, on the other hand, provide practical approaches to applying DDD principles in the context of aggregates. They offer techniques and patterns that address common challenges faced during the design and implementation of aggregates.
By leveraging best practices and implementation strategies, developers can overcome complexities and pitfalls associated with aggregates, resulting in more robust and maintainable domain models. Let's explore some of these practices and strategies in the following sections.
Designing DDD Aggregates
Designing DDD aggregates requires careful consideration of the boundaries, relationships, and responsibilities within the domain model. In this section, we will explore best practices and implementation strategies for designing DDD aggregates that are focused, cohesive, and consistent.
Identifying Aggregate Boundaries and Relationships
One of the key aspects of designing DDD aggregates is identifying the boundaries and relationships between objects within the domain model. An aggregate should encapsulate a cluster of related entities and value objects that work together to fulfill a specific business concept. By defining clear aggregate boundaries, we can ensure that the responsibilities and behavior of objects are properly encapsulated.
To identify aggregate boundaries, it is crucial to analyze the domain requirements and understand the business concepts involved. Look for natural groupings of objects that have strong consistency requirements and need to be modified together as a unit. These boundaries should be based on the business context and not solely on technical considerations.
Additionally, it is essential to establish relationships between aggregates carefully. While aggregates can reference other aggregates, it is advisable to minimize cross-aggregate relationships to maintain consistency and scalability. Instead, focus on designing aggregates that can operate independently as much as possible, ensuring loose coupling between different parts of the domain model.
Applying the Single Responsibility Principle to DDD Aggregates
The Single Responsibility Principle (SRP) is a fundamental principle in software design, and it applies to aggregates as well. Each aggregate should have a clear and well-defined responsibility, representing a cohesive business concept or transactional unit. By adhering to SRP, we ensure that aggregates have a focused purpose, making them easier to understand, test, and maintain.
When designing aggregates, consider the core behaviors and invariants associated with the business concept they represent. Avoid including unrelated behaviors or functionalities within an aggregate, as it can lead to unnecessary complexity and coupling. Instead, distribute responsibilities among different aggregates and establish clear boundaries between them.
Establishing Consistency and Invariants within DDD Aggregates
Aggregates play a crucial role in maintaining consistency and enforcing invariants within the domain model. An invariant represents a rule or condition that must always hold true within an aggregate. It ensures data integrity and prevents invalid states or operations.
When designing aggregates, pay careful attention to the consistency requirements and invariants of the business domain. Define rules and constraints that must be satisfied by the aggregate's entities and value objects. By encapsulating these rules within the aggregate, you establish a strong consistency boundary that guarantees the integrity of the data and behavior.
To enforce consistency and invariants, aggregates should provide clear methods for modifying their internal state. By encapsulating the modification logic within the aggregate, you can ensure that any changes made to the aggregate's data adhere to the defined rules. This promotes a more reliable and predictable behavior of the domain model.
Defining DDD Aggregate Roots
Understanding the Role of Aggregate Roots
An aggregate root serves as the entry point to an aggregate and represents the primary entity that controls and encapsulates the consistency and integrity of the entire aggregate. All interactions with the aggregate, including modifications and queries, should go through the aggregate root. It acts as a gateway for enforcing business rules and maintaining invariants within the aggregate.
Aggregate roots provide a clear point of reference for the aggregate, making it easier to navigate and understand the domain model. They serve as a focal point for establishing transactional boundaries and encapsulating behavior and data that are critical to the business.
Determining When to Use an Entity or a Value Object as an Aggregate Root
When deciding whether to use an entity or a value object as an aggregate root, consider the lifecycle and identity of the object in question. Entities are objects with unique identities that can change their state over time. On the other hand, value objects represent immutable, replaceable, and self-contained values.
Typically, it is preferable to choose an entity as the aggregate root when there are significant behaviors and operations associated with the object that goes beyond its mere value. Entities provide identity and lifecycle management, allowing them to maintain relationships and participate in domain operations.
Value objects, on the other hand, are suitable as part of an aggregate but are not typically used as aggregate roots. Value objects contribute to the state and behavior of an aggregate but do not have an identity of their own. They are immutable and can be freely shared and reused within the aggregate.
When deciding on the aggregate root, it is crucial to consider the business context, the nature of the object, and the interactions it has with other objects within the aggregate. Choose the option that best aligns with the behavior, identity, and lifecycle of the object in question.
Ensuring DDD Aggregate Root Integrity and Consistency
Maintaining integrity and consistency within aggregate roots is essential to ensure the correctness and reliability of the domain model. The aggregate root should enforce rules and invariants that apply to the entire aggregate, ensuring that the internal state remains valid.
To ensure aggregate root integrity, encapsulate the modification logic within the root itself. Any changes or modifications to the aggregate's state should be performed through explicit methods defined by the root. By doing so, you centralize the responsibility for maintaining invariants and make it clear which operations are allowed and how they affect the aggregate.
Additionally, aggregate roots should be responsible for managing relationships and ensuring the consistency of related entities and value objects. The aggregate root acts as a gateway for manipulating and enforcing rules within these relationships, ensuring that the aggregate remains in a valid and consistent state.
By properly defining aggregate roots and their responsibilities, you establish clear transactional boundaries, enforce business rules, and maintain data consistency within the domain model.
Handling Aggregate Changes
When working with Domain-Driven Design (DDD) aggregates, effectively managing and handling aggregate changes is crucial. In this section, we will explore best practices and implementation strategies for managing complex business operations within aggregates, maintaining consistency during modifications, and leveraging event sourcing and event-driven architecture with aggregates
Managing Complex Business Operations within Aggregates
Aggregates often represent complex business concepts that involve intricate operations and workflows. To effectively manage these operations, it is important to design aggregates with a clear focus on their responsibilities and behaviors.
Identify the key business operations that the aggregate needs to support and encapsulate them within the aggregate itself. This allows for better organization and encapsulation of the domain logic related to those operations. By keeping the operations within the aggregate, you ensure that the aggregate remains responsible for its own consistency and invariants.
Furthermore, consider breaking down complex operations into smaller, more manageable steps within the aggregate. This promotes readability, maintainability, and reusability of the aggregate's code. It also allows for easier testing and debugging of individual steps, enhancing the overall robustness of the aggregate.
Maintaining Consistency during Aggregate Modifications
Maintaining consistency during modifications is a critical aspect of working with aggregates. As aggregates encapsulate a group of related entities and value objects, it is essential to ensure that any modifications made to the aggregate maintain the integrity of its internal state.
To maintain consistency, enforce business rules and invariants within the aggregate. Define constraints and validation checks that must be satisfied when modifying the aggregate's state. By encapsulating these rules within the aggregate, you can guarantee that its state remains valid and consistent throughout the modification process.
It is also important to handle cascading changes within the aggregate. When modifying an entity or value object within the aggregate, ensure that any dependent objects or related entities are appropriately updated to reflect the changes. This ensures that the aggregate remains in a consistent state, preventing any data inconsistencies or conflicts.
Implementing Event Sourcing and Event-Driven Architecture with DDD Aggregates
Event sourcing and event-driven architecture are powerful techniques that can be applied to aggregates to enhance their design and implementation.
Event sourcing involves capturing and storing a sequence of events that represent changes to the aggregate's state. By storing events rather than the current state, you have a historical log that can be replayed to reconstruct the aggregate's state at any given point in time. This provides a reliable audit trail and enables time-traveling queries, making it easier to understand past behaviors and debug issues.
Event-driven architecture complements event sourcing by leveraging events to enable loose coupling and asynchronous communication between different parts of the system. Events emitted by aggregates can be consumed by other components, triggering actions or updates based on the changes in the aggregate's state. This decoupling of components promotes scalability, extensibility, and flexibility in the system's architecture.
By incorporating event sourcing and event-driven architecture, you can enhance the modularity, scalability, and maintainability of aggregates, while also ensuring consistent behavior and auditability of the domain model.
Implementing Repositories for DDD Aggregates
Repositories play a crucial role in managing the persistence and retrieval of aggregates in Domain-Driven Design (DDD). In this section, we will explore best practices and implementation strategies for implementing repositories, including storing and retrieving aggregates, designing repository interfaces and implementations, and considering caching and performance aspects.
Storing and Retrieving Aggregates Using Repositories
Repositories provide a bridge between the domain model and the data persistence layer, enabling the storage and retrieval of aggregates. They encapsulate the logic for interacting with the underlying data store, shielding the domain model from the specific details of the persistence mechanism.
When storing aggregates, repositories should ensure that the aggregate's state is persisted in a consistent and reliable manner. The repository should handle the necessary operations, such as creating, updating, and deleting aggregates, while ensuring data integrity and enforcing any necessary validation rules.
Retrieving aggregates from repositories involves querying the data store based on specific criteria or identifiers. Repositories should provide methods that allow clients to retrieve aggregates by their unique identifiers or other relevant search parameters. The repository should then assemble the retrieved data into aggregates and return them to the caller.
Designing Repository Interfaces and Implementations
When designing repository interfaces, it is essential to focus on the specific needs of the domain model and the operations required for working with aggregates. Define methods that align with the use cases and requirements of the application, ensuring that the interface provides a clear and intuitive API for working with repositories.
Consider including methods for creating, updating, and deleting aggregates, as well as retrieving them based on various criteria. Additionally, think about incorporating query methods that enable querying aggregates based on specific domain-specific filters or conditions.
When implementing repository interfaces, the choice of the underlying data storage technology is crucial. Select a data persistence mechanism that aligns with the requirements of the application, such as a relational database, NoSQL database, or an in-memory storage system. Implement the repository methods using appropriate data access techniques and ensure that the necessary transactional and consistency guarantees are maintained.
Caching and Performance Considerations for Repositories
Caching can be a valuable technique to improve the performance and scalability of repositories. By caching frequently accessed aggregates or query results, you can reduce the load on the data store and improve response times. However, it is important to carefully consider the caching strategy and its impact on data consistency and integrity.
Implement caching at an appropriate level, such as within the repository or at a higher-level caching layer. Evaluate the cache eviction policies based on the frequency of data updates and the importance of data freshness. Employ caching mechanisms that support invalidation or refresh strategies to ensure that the cached data remains accurate and up to date.
Performance considerations also come into play when working with repositories. Optimize database queries and data access patterns to minimize the number of roundtrips and maximize the efficiency of data retrieval. Consider techniques like lazy loading or eager fetching to balance the trade-offs between performance and data load.
Regularly monitor and tune the repository performance by analyzing query execution plans, identifying bottlenecks, and optimizing database indexes or data access strategies when needed.
Best Practices for DDD Aggregates
Designing and implementing Domain-Driven Design (DDD) aggregates requires following best practices that promote maintainability, scalability, and consistency. In this section, we will explore key best practices for working with DDD aggregates, including keeping aggregates small and focused, minimizing inter-aggregate relationships, avoiding data duplication, and applying event-driven architecture principles.
Keeping Aggregates Small and Focused
To ensure clarity and maintainability, it is crucial to keep aggregates small and focused on a single business concept. Aggregates should represent cohesive and bounded contexts within the domain model. By keeping aggregates focused, you minimize complexity, improve understandability, and make it easier to reason about the behavior and responsibilities of each aggregate.
Avoid the temptation to include unrelated entities or value objects within an aggregate. Instead, distribute responsibilities among multiple aggregates, each having a clear purpose and a well-defined set of entities and value objects. This separation of concerns helps maintain the integrity and consistency of the domain model, making it easier to evolve and extend in the future.
Minimizing Inter-Aggregate Relationships
Inter-aggregate relationships should be minimized to reduce coupling and enhance scalability in your domain model. Instead of directly referencing objects in other aggregates, focus on using aggregate roots as points of interaction between aggregates.
When multiple aggregates need to communicate or collaborate, consider leveraging event-driven architecture and domain events. By raising events within an aggregate and allowing other aggregates to subscribe to those events, you can establish loose coupling and decouple the timing and order of operations between aggregates.
Avoiding Data Duplication within Aggregates
Avoid data duplication within aggregates to ensure consistency and reduce the risk of data inconsistencies. Each piece of data should be stored and managed in a single authoritative location within the domain model. Duplicating data within aggregates can lead to data discrepancies and introduce maintenance challenges when updating or modifying the data.
Instead, design aggregates to reference the necessary entities and value objects through unique identifiers or references. This promotes data consistency by ensuring that aggregates always refer to the most up-to-date version of the data. When retrieving aggregates, use appropriate mechanisms, such as lazy loading or eager fetching, to populate the required data without duplicating it.
Applying Event-Driven Architecture Principles to Aggregates
Event-driven architecture (EDA) can greatly enhance the scalability, responsiveness, and extensibility of DDD aggregates. By leveraging domain events, you can decouple the processing and reaction to business events within aggregates, promoting loose coupling and flexibility.
When implementing aggregates, identify the key domain events that should be raised when certain conditions or state changes occur. By emitting these events, other parts of the system can react and respond accordingly. Domain events provide a means of communication and coordination between aggregates, allowing them to evolve independently and ensuring consistency within the system.
Applying EDA principles to aggregates can result in a more resilient and flexible architecture. It enables better scalability by distributing processing across multiple components and promotes a loosely coupled design that allows for independent evolution and maintenance of aggregates.
Implementation Strategies for DDD Aggregates
Implementing Domain-Driven Design (DDD) aggregates requires thoughtful strategies to ensure effective communication, separation of concerns, and historical analysis. In this section, we will explore implementation strategies for DDD aggregates, including using domain events to communicate changes, applying Command-Query Responsibility Segregation (CQRS) with aggregates, and leveraging event sourcing for auditing and historical analysis.
Using Domain Events to Communicate Aggregate Changes
Domain events provide a powerful mechanism for communicating changes and propagating information within the system. By using domain events, aggregates can publish events when significant state changes occur, and other components can subscribe to those events to react accordingly.
When implementing aggregates, identify the important events that occur within an aggregate's lifecycle. For example, an Order aggregate might emit events such as OrderPlaced, OrderUpdated, or OrderCancelled. These events capture the important state changes and can trigger actions in other aggregates or external systems.
By leveraging domain events, you promote loose coupling and ensure that aggregates remain focused on their core responsibilities. Other components can react to the events and update their own state or trigger business processes, maintaining consistency throughout the system.
Applying CQRS (Command-Query Responsibility Segregation) with Aggregates
CQRS is a design pattern that separates the responsibilities for reading (queries) and writing (commands) data. Applying CQRS to aggregates can bring several benefits, including improved performance, scalability, and flexibility.
With CQRS, you split the models and logic for read operations and write operations into separate components. The read side focuses on providing efficient querying and retrieval of data, while the write side handles the modification and persistence of aggregates.
By segregating the responsibilities, you can optimize each side independently. The read side can be tuned for fast querying and denormalized views, while the write side can focus on maintaining consistency and enforcing business rules. This separation allows for scaling and evolving the system in a more controlled and targeted manner.
When applying CQRS to aggregates, carefully consider the synchronization between the read and write models. Choose appropriate synchronization mechanisms, such as eventual consistency or event-driven updates, to ensure that the read side reflects the latest changes made on the write side.
Applying Event Sourcing for Auditing and Historical Analysis
Event sourcing is a technique where instead of storing the current state of an aggregate, you store a sequence of events that represent changes to the aggregate's state. This approach provides a historical log of events, allowing you to rebuild the aggregate's state at any given point in time.
By applying event sourcing to aggregates, you gain several benefits, including auditing capabilities, the ability to time-travel through the aggregate's state history, and the potential to derive additional insights from the event stream.
Events can be stored in an event store or a durable log, ensuring the reliability and durability of the historical data. To rebuild an aggregate's state, you replay the events in the sequence they occurred, applying them to the aggregate to reconstruct its state at any specific point in time.
Event sourcing also facilitates historical analysis and the ability to derive projections and analytics from the event stream. You can process the events asynchronously and derive insights or perform calculations based on the event data.
When implementing event sourcing with aggregates, ensure that the event store and replay mechanisms are designed for efficiency and scalability. Consider using techniques like snapshotting to optimize the rebuilding process when dealing with large event streams.
Conclusion
In this blog post, we have explored the best practices and implementation strategies for working with Domain-Driven Design (DDD) aggregates. We have discussed various aspects of DDD aggregates, including their definition, importance, design principles, implementation strategies, and benefits. Let's recap the key takeaways and conclude our discussion on DDD aggregates.
Throughout this blog post, we have covered several best practices and implementation strategies for DDD aggregates, including:
- Designing aggregates that are small, focused, and cohesive.
- Minimizing inter-aggregate relationships to reduce coupling.
- Avoiding data duplication within aggregates to maintain consistency.
- Applying event-driven architecture principles for communication and loose coupling.
- Leveraging domain events to communicate changes and enable reactive systems.
- Implementing Command-Query Responsibility Segregation (CQRS) to separate read and write operations.
- Utilizing event sourcing for auditing, historical analysis, and state reconstruction.
By following these practices and strategies, you can create well-designed and maintainable DDD aggregates that accurately represent the business domain and promote flexibility and scalability in your software systems.
Domain-Driven Design, and specifically the proper implementation of aggregates, is a powerful approach to building software systems that align closely with real-world domains. As you embark on your domain modeling journey, we encourage you to apply the principles and strategies discussed in this blog post.
By keeping aggregates small, cohesive, and focused, you can create a more understandable and manageable domain model. Minimizing inter-aggregate relationships and avoiding data duplication helps maintain consistency and simplifies the evolution of the system over time. Embracing event-driven architecture, CQRS, and event sourcing brings scalability, flexibility, and valuable insights to your domain model.
Using DDD aggregates brings numerous benefits to software development:
- Improved Domain Modeling: DDD aggregates help model complex domains effectively, capturing business concepts and enforcing consistency boundaries.
- Maintainability and Extensibility: Well-designed aggregates make the domain model more maintainable and easier to extend as the business requirements evolve.
- Scalability and Performance: Properly implemented aggregates, along with strategies like event-driven architecture and CQRS, promote scalability and improve performance by separating concerns and optimizing data access.
- Auditing and Historical Analysis: Event sourcing allows for auditing capabilities and the ability to analyze the history of changes to the aggregate's state.
By embracing DDD aggregates and implementing them with best practices and implementation strategies, you can create software systems that accurately model the business domain, are more maintainable, and can adapt to changing business needs effectively.